
One of my long-time brick walls is my 3rd great-grandfather Jacob Garber. He is an ancestor on my Dad’s side. I have written about the rather sparse information I have been able to gather on him and the challenges in finding his parents in the brick wall section of my website. [Here is the link: bit.ly/jacob-garber-bw]
This is essentially what I know about him. He was born circa 1802, probably in the area of Amity or Douglassville, Berks County, Pennsylvania. He married Ann Campbell on 13 Nov 1825. Ann died in 1850 and was survived by six children – five daughters and one son. Despite the oldest daughter Mary Ann being born in Oct of 1825, all of Ann Campbell Garber’s children are presumed to be fathered by Jacob. At this point I am not sure when Jacob died. It is possible that he remarried after Ann’s death and fathered additional children.
So what’s the big break through with DNA? Well I have a AncestryDNA match who also has Jacob Garber and Ann Campbell in his tree. I have been in contact with him, but unfortunately he doesn’t know the parents of Jacob either. If my match would not have uploaded his DNA test results to GEDMatch that would be the end of the story – at least for now. But because of the chromosome-level matching information that we get through GEDMatch we now have a triangulation group that points to possible parents for Jacob!!

But there’s a twist. As I mentioned in an earlier post, I have created paternal and maternal side kits on GEDMatch by phasing my original kit with my Mom’s. When I do a one to one comparison between my paternal & maternal side kits I get a 21.3 cM match on Chromosome 11. I was not surprised (nor upset) by this because I have known for several years that both my Mom and Dad descend from Valentine Keely & wife Susanna Mueller as well as from George Bechtel & Hannah Yocum. Both of these couples lived in the 1700s. Thus, in one case my parents are 5th cousins once removed and in the other case 6th cousins once removed.
As you have probably guessed by now, my Jacob Garber-Ann Campbell match (let’s call him EK) matches me on that very same segment where my two chromosome 11s match each other. EK, of course, also matches my Mom on that segment and matches my maternal uncle on part of the segment. So the main triangulation group is my Dad (via the segment I inherited from him), my Mom and EK. How awesome is that! (Note that recently my brother and a maternal Aunt tested and they share this segment as well!)
We first need to look at the match itself. I have a couple of graphics from GEDmatch to illustrate the match from the perspective of my paternal side as well as my maternal side. The first graphic shows the match based on what I inherited from my Dad. Leaving my Uncle out of the equation (for the moment), it is easy to see that EK has the exact same match to my paternal side kit as my Mom and I. It is also obvious that the matching segment crosses over the centromere and I’ll address that shortly.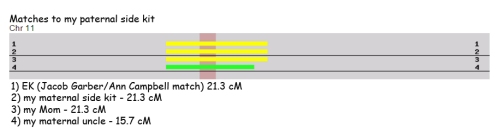 The second graphic shows the match based on what inherited from my Mom. I think the interesting thing to note is that this match to EK is slightly longer than the match based on my Dad’s side.
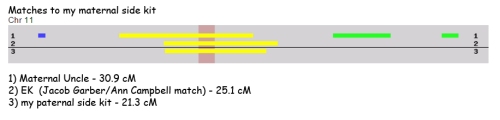
The second graphic shows the match based on what inherited from my Mom. I think the interesting thing to note is that this match to EK is slightly longer than the match based on my Dad’s side.
 Getting back to the centromere. If you have ever seen a graphic with a chromosome represented by an X-like figure, the centromere would be where the legs of the X connect. It is represented by the pinkish colored vertical band. It is also a region where recombination doesn’t generally occur and could be passed down unchanged for many, many generations. So a match on that area of the chromosome is usually considered a false positive in that it may not indicate a common ancestor in a genealogical time frame.
Getting back to the centromere. If you have ever seen a graphic with a chromosome represented by an X-like figure, the centromere would be where the legs of the X connect. It is represented by the pinkish colored vertical band. It is also a region where recombination doesn’t generally occur and could be passed down unchanged for many, many generations. So a match on that area of the chromosome is usually considered a false positive in that it may not indicate a common ancestor in a genealogical time frame.
That being said the matching segments as pictured above extend well beyond the centromere and I believe they represent true IBD segments. In fact the Ancestry matching algorithm, which is supposed to be designed to subtract false positive areas, classifies my match to EK as 4th-6th cousin with shared DNA being a total of 18.6 cM across 2 segments. Kind of curiously, it classified both my Mom’s and Uncle’s match to EK as 5th-8th cousin, with a total of 15.6 cM across 2 segments and 14.9 across 2 segments, respectively. Given the results shown on GEDmatch, I would have expected my Mom’s match to EK to have been closer in length to mine, but for one reason or another Ancestry has not calculated it that way.
So getting back to the Garber connection. As it turns out, there are Garbers in my mother’s ancestry. One of her 3rd great-grandparents (my 4th great) are Conrad Garber and Anna Maria Bechtel. From Chester County, Pennsylvania estate documents we know that Conrad had a brother named John who died prior to 1837 leaving 12 children. The children are named in the probate file of their bachelor uncle Johan Adam Garber, as are the children of Conrad.
I have found baptism records for some of John Garber’s children, but not all of them. One of the children for whom I have not located a baptism record is the son named Jacob. For several years I have been wondering if Jacob, son of John, was the Jacob who married Ann Campbell. The approximate age is right and the location is right, but with multiple Garber families in the area I have felt that more evidence was needed to make that call. This DNA match is nudging me closer.
Going back a generation, the parents of Conrad, John and Johan Adam Garber were Johan Adam Garber and Anna Maria Schleicher. Assuming for now that Jacob is the son of John, my relationship to EK via my Mom’s side is sixth cousin once removed. The relationship on my Dad’s side is fourth cousin. A nagging issue is why my maternal side kit seems to share slightly more DNA with EK even though the relationship is more distant. I have a few thoughts on this. First, the randomness of DNA inheritance and recombination causes you to share more (or less) than the average amount expected at a given cousin level. Second, the fact that this matching segment crosses the centromere could have the effect of making it more “sticky” than if it were located elsewhere on the chromosome. Also, the Ancestry algorithm calculated a larger shared DNA amount between EK and me than between EK and my Mom and that is consistent with the actual relationships. So maybe whatever it does to strip out false positive regions is working in this case.
The bottom line is that I am cautiously optimistic that I have found Jacob’s parents – and a third common ancestor couple for my parents. However, there is still more work to be done to be sure the match is not inherited from Jacob’s wife Ann. While I have fairly good information on her paternal side, her maternal side is yet another brick wall. There is always the possibility, however remote, that Ann’s mother connects back to one of my known pedigree intersections – i.e. Valentine Keely/Susannah Mueller or George Bechtel/Hannah Yocum or an as yet unknown common ancestor shared by my parents. (Note that because EK descends from a daughter of Jacob & Ann who moved west (not the one born prior to the marriage), the chance of a link through another of EK’s ancestors is extremely remote.)
That all being said, I’m not a DNA expert so if someone reading this has other ideas or thinks I’m off-base, I would love to hear from you!






