
In my previous post (link), I started the discussion of sources and citations and lumping and splitting as related to creating sources in Legacy Family Tree software. Part 2 will talk a little about the database structure and the trade-0ffs of lumping and splitting.
I made a very simplistic, high-level diagram of how things work in Legacy. It shows a source table with 5 sources. Next is the Citation Table which shows 5 citations all pointing back to source 1. Notice, however, the first three of these citation records contains identical data. This identical data is stored three times because each one points to a different event. The 4th and 5th Citation Data records are also identical.
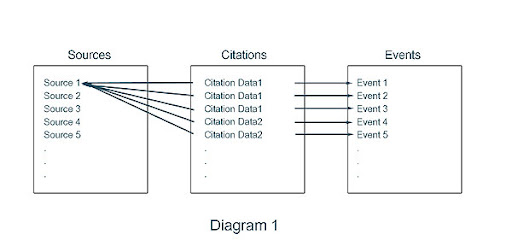
This data model involves redundant storage of data and is very bad in terms of data maintainability. Now, in order to maintain data integrity, if any piece of the citation data needs to be changed it is necessary to find all copies and change each of them. Legacy shifts this onus of maintaining data integrity to the user, supplying only a Search and Replace tool. But there are several cases where Search and Replace cannot make the desired change easily and some cases where it cannot make the desired change at all. It then falls on the user to edit each copy of the citation data manually.
Diagram 2 illustrates the exact same relationships, but the citation data/event links are pulled out into a separate table. This allows for each unique citation record to be stored once, regardless of the number of events to which it is linked.
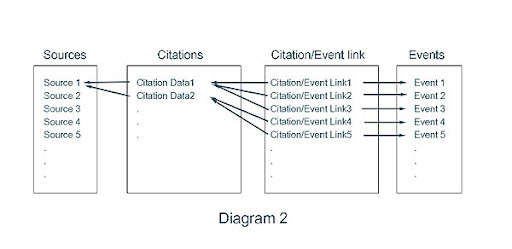
Had Legacy implemented a model similar to diagram 2, I would be a very happy camper. But they didn’t. So now it all comes down to trade-offs. On one hand become a splitter. This entails creating a multitude of very specific, repetitious sources and minimizing the citation data content. In many, but not all cases, it gets rid of the data integrity problem as described above. On the downside, since you have so many sources, you need to be very careful and vigilant when you create them so that all the repetitious data is consistent from one source to the next. (That is if you care about consistent wording and formatting.) Admittedly, the ability to create a new source by copying an existing one helps with this.
It is also extremely important to come up with an organization scheme that is built into the source name. All Legacy does is present you with an alphabetized list of sources – no filtering or classification on the list. Granted, this is also a problem for lumpers, but the problem is magnified for splitters because they have so many more sources! Over the past couple of years, I’ve tweaked my naming system a couple of times to force the sort order of the source list. I don’t want to even image how much more laborious and time-consuming this would have been were I an extreme splitter! And while I don’t know of a hard-limit on sources, if you have a large database of people you may find that extreme splitting creates just too many sources to be practical.
On the flip-side. lumpers are more likely to have a more manageable number of sources. This has the advantage of making it somewhat easier to tweak them. I have actually tweaked my naming convention to force sort order (as mentioned above) as well as tweaked wording and content of source fields for better consistency in how footnotes and endnotes appear in reports. I also feel that some degree of lumping is more in keeping with database and software design principles. The downside of lumping is, of course, the citation maintainability problem which is the focus of the article.
So where does all this leave me. Well, I’ve already characterized myself as a lumper – although I am sure there are some who are more extreme. Over the years I’ve done a lot of experimenting and tweaking and I like the system I have for deciding what to include in the source table vs what to include in the citation. What works best for me is to define a source for each dataset or data collection. So each database in Ancestry gets their own source. I also tend to create separate sources for each of the datasets stored on the USGenWeb county pages. On the splitter/lumper spectrum, I would say that I’m a moderate lumper. In terms of Source Writer, I have recently decided to primarily use just 2 templates for online data – online database or online database with images. (But that’s starting to get into a whole other discussion — the multitude of source writer templates!)
My struggle with Legacy sourcing is nothing new. It’s an issue I’ve had to deal with from the time I first started using it back in early 2004. Based on what people say on the LUG email list, the database implementation has pushed some people toward extreme splitting. That never felt right to me, and by now I’m just too entrenched in the way I have been doing things to even consider changing. Why then did I bother writing this post? After creating the SAR source and citation and linking it to about 30 events (so 30 copies of the citation) it occurred to me I should have included something additional in the citation. I tried to fix it with search and replace and guess what — it didn’t work!!!! It said it found and made 30 changes, but when I looked at the data, it had NOT changed. So mostly out of frustration I wrote this post. I still have to go back and try to fix things up, but at least I had a chance to vent.
Maybe some day Legacy will fix this design. Maybe some day some other company will design and build genealogy software that does not have this issue. Maybe some company already has — sometimes it’s hard to tell from the marketing oriented data on their websites. Maybe somebody will see this post and let me know!!





